
El debate sobre cuál es la «mejor IA» se ha vuelto obsoleto. El panorama de la IA en 2025 ya no es una simple carrera hacia la cima, sino la divergencia estratégica de tres titanes hacia dominios especializados. Este informe sirve como una guía definitiva para este nuevo y multipolar mundo de la IA, diseñado para ayudar a desarrolladores, investigadores y líderes tecnológicos a navegar por un ecosistema cada vez más complejo y matizado.
Presentamos a los contendientes que se van a enfrentar a la mejor IA del 2025:
Claude 4 de Anthropic: El maestro arquitecto de software, construido específicamente para la codificación agéntica compleja y una fiabilidad de nivel empresarial, con un fuerte énfasis en la seguridad
GPT-4o de OpenAI: El versátil y rentable «omni-modelo», diseñado para la adopción masiva y una interacción hombre-máquina fluida y de baja latencia.
Gemini 2.5 Pro de Google: El analista devorador de datos, definido por su colosal ventana de contexto y su destreza multimodal nativa, capaz de procesar y comprender vastas cantidades de información.

📊 Comparativa de las mejores IA
Cuadro de Mando de Benchmarks (Mejor IA 2025)
| Benchmark | Dominio | GPT-4o | Claude 4 Opus | Gemini 2.5 Pro | Ganador/Análisis |
| MMLU (5-shot) | Conocimiento General | 87% | 86% | 86.4% (en GPQA) | GPT-4o/Claude 4 lideran, mostrando un razonamiento general de primer nivel. |
| MMLU-Pro | Razonamiento Avanzado | ~72.8% | ~70.1% | (No disponible) | GPT-4o muestra una ligera ventaja en esta prueba más difícil. |
| GPQA Diamond | Ciencia Experta | (No disponible) | (No disponible) | 86.4% | Gemini sobresale en el conocimiento científico profundo. |
| SWE-bench Verified | Codificación Agéntica | 54.6% (GPT-4.1) | 72.5% | 63.8% | Claude 4 es el ganador decisivo en codificación del mundo real. |
| HumanEval (pass@1) | Codificación Algorítmica | 92.7% | 82.9% | 89.0% | GPT-4o lidera en tareas de codificación algorítmica más simples. |
| MMMU (Validación) | Razonamiento Visual | 82.9% (o3) | 76.5% | 79.6% | OpenAI/Google lideran en comprensión visual. |
⚡ Capacidades Técnicas de la mejor IA
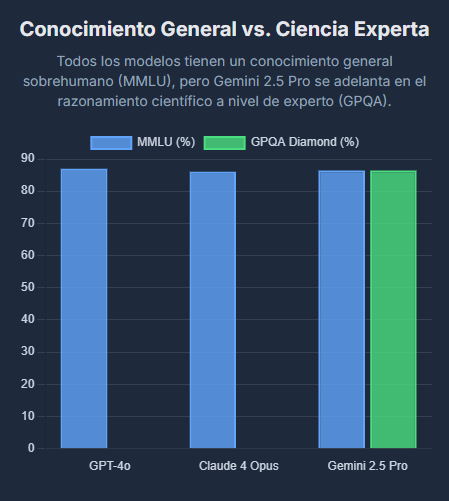
Los tres modelos rinden a niveles cercanos o sobrehumanos en pruebas de conocimiento general como MMLU, lo que indica una base de conocimiento extremadamente sólida en todos ellos. Sin embargo, la especialización comienza a emerger en pruebas más exigentes. En benchmarks de nivel experto como GPQA, que evalúa preguntas de ciencia a nivel de doctorado, Gemini 2.5 Pro muestra una ventaja distintiva.
Este rendimiento superior probablemente se deba a su profunda integración con el vasto grafo de conocimiento de Google y los datos de investigación, lo que le permite acceder y sintetizar información especializada con mayor precisión. Un gráfico de barras que visualice las puntuaciones de MMLU y GPQA mostraría a los tres modelos agrupados en MMLU, pero a Gemini 2.5 Pro destacando en GPQA.
💻 Rendimiento en Programación y Código
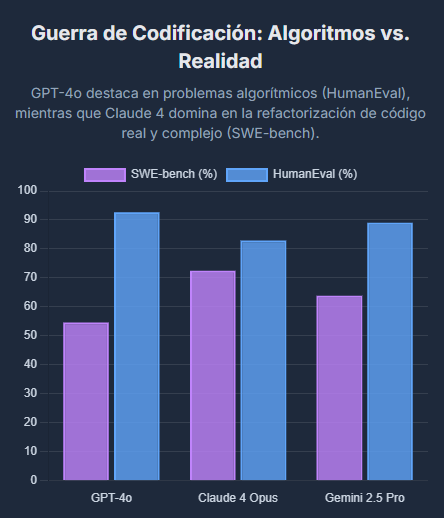
Es en el ámbito de la codificación donde la especialización se vuelve más evidente y crítica. Los resultados contradictorios entre diferentes benchmarks revelan una distinción crucial para encontrar la mejor IA:
- HumanEval: GPT-4o y Gemini 2.5 Pro lideran en este benchmark, que prueba la capacidad de generar funciones de código correctas y autocontenidas a partir de descripciones. Esto sugiere que son excelentes para generar fragmentos de código algorítmico, resolver problemas de tipo LeetCode o ayudar en tareas de scripting.
- SWE-bench: Claude 4 Opus y Sonnet dominan este benchmark de manera decisiva. SWE-bench es una prueba mucho más realista del trabajo de un ingeniero de software, ya que requiere que el modelo comprenda y corrija errores dentro de grandes bases de código existentes de GitHub.
Los resultados divergentes entre HumanEval y SWE-bench no son una contradicción, sino una revelación: la elección de un modelo para «codificar» depende del tipo de codificación. Una puntuación alta en HumanEval se correlaciona con la capacidad de resolver problemas bien definidos y a pequeña escala. Por otro lado, una puntuación alta en SWE-bench se correlaciona con la capacidad de razonar sobre sistemas complejos e interconectados, el núcleo de la ingeniería de software moderna.
Esto permite ofrecer un consejo más matizado: para scripting rápido y problemas algorítmicos, GPT-4o es una opción excelente y rentable. Para refactorizar un sistema heredado o depurar una arquitectura de microservicios compleja, Claude 4 es la herramienta superior. Un gráfico de barras que visualice las puntuaciones de SWE-bench y HumanEval pondría de relieve esta brecha de rendimiento, mostrando a GPT-4o a la cabeza en HumanEval y a Claude 4 muy por delante en SWE-bench.
Rendimiento en voz y audio de la mejor IA
La entrada/salida por voz es otro campo de batalla. GPT-4o fue el primer modelo diseñado para audio nativo: OpenAI informa que responde en voz en ~232 ms, logrando interacciones habladas tan naturales como humanas. ChatGPT ya integra GPT-4o con modo de voz en varios idiomas. Google ofrece Gemini Live, un asistente por voz integrado en Android que soporta español e incluye búsquedas integradas
. Anthropic ha lanzado el modo voz de Claude Sonnet 4: permite conversaciones habladas en iOS/Android, con 5 voces sintéticas personalizables, transcripción en tiempo real y cambio de texto fluido ↔ voz. Sin embargo, actualmente el modo voz de Claude solo responde en inglés. En la práctica: GPT-4o y Gemini ya permiten diálogos de voz en español, mientras que Claude habla en inglés con alta calidad (múltiples voces, resúmenes automáticos)
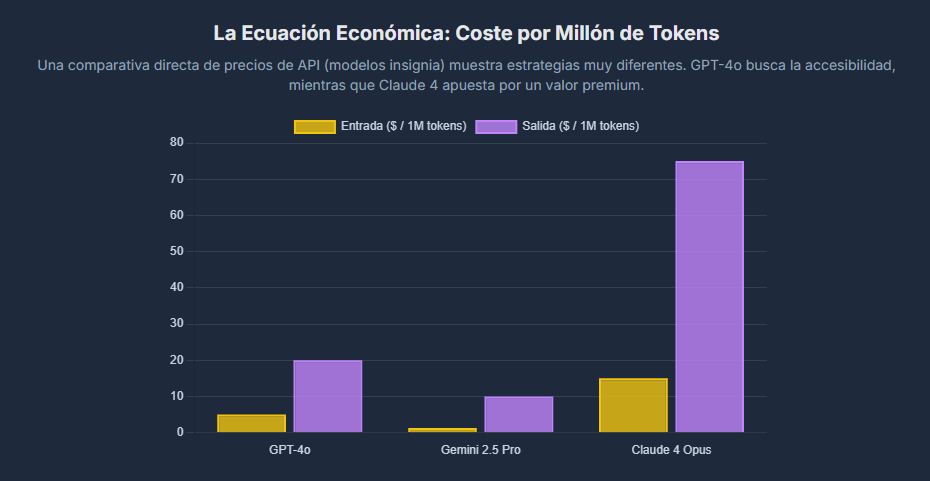
La Ecuación Económica: Precios de API, Valor y Coste Total de Propiedad
Una simple comparación de precios por token es engañosa. La verdadera decisión económica se basa en el «Coste Total de la Solución», que tiene en cuenta el rendimiento del modelo, la velocidad y, lo que es más importante, el coste del tiempo del desarrollador.
La siguiente tabla es una guía de referencia financiera esencial. Permite a un desarrollador o director de tecnología evaluar inmediatamente los costes directos asociados a cada modelo y tomar decisiones conscientes del presupuesto.
Precios de API y Especificaciones del Modelo (Mediados de 2025)
| Familia de Modelos | Variante del Modelo | Precio de Entrada ($/1M tokens) | Precio de Salida ($/1M tokens) | Ventana de Contexto |
| OpenAI | GPT-4o | $5.00 | $20.00 | 128K |
| GPT-4o mini | $0.15 | $0.60 | 128K | |
| GPT-4.1 | $2.00 | $8.00 | 1M | |
| Gemini 2.5 Pro | $1.25 (≤200k) / $2.50 (>200k) | $10.00 (≤200k) / $15.00 (>200k) | 1-2M | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | |
| Anthropic | Claude 4 Opus | $15.00 | $75.00 | 200K |
| Claude 4 Sonnet | $3.00 | $15.00 | 200K |
Recomendaciones Estratégicas para la Aplicación en el Mundo Real
Esta sección final sintetiza todos los datos anteriores en recomendaciones claras y accionables, adaptadas a arquetipos de usuarios específicos. Responde a la pregunta fundamental del usuario: «¿Qué IA debo usar?».
La siguiente matriz es la herramienta de toma de decisiones definitiva para el lector. Traduce los benchmarks y precios abstractos en recomendaciones concretas para tareas empresariales y creativas comunes, proporcionando una conclusión práctica e inmediata.
Matriz de Idoneidad por Caso de Uso
| Caso de Uso | GPT-4o | Gemini 2.5 Pro | Claude 4 | Justificación |
| Refactorización de Bases de Código Complejas | Medio | Medio | Alto | Puntuación superior en SWE-bench y arquitectura agéntica. |
| Análisis de Documentos a Gran Escala | Bajo | Alto | Medio | Ventana de contexto inigualable de 2M de tokens. |
| Generación de Contenido Creativo | Alto | Medio | Medio | Mejor para narrativas atractivas y de estilo humano. |
| Aplicaciones Empresariales de Seguridad Crítica | Medio | Medio | Alto | IA Constitucional y enfoque en la fiabilidad. |
| Chatbot/Automatización de Alto Volumen | Alto | Alto | Medio | GPT-4o mini y Gemini Flash ofrecen el mejor rendimiento-coste a escala. |
| Investigación y Análisis Científico | Medio | Alto | Medio | Sobresale en ciencia de nivel experto (GPQA) y puede procesar estudios enteros. |
| Interacción Multimodal en Vivo | Alto | Medio | Bajo | Diseñado para interacción de voz/vídeo en tiempo real y de baja latencia. |
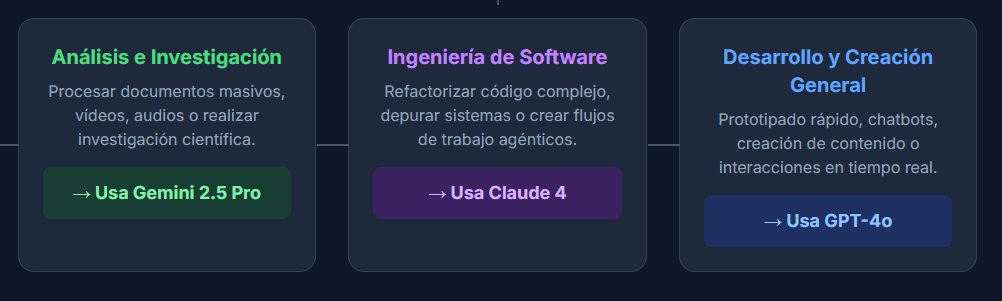
Recomendaciones por Arquetipo de Usuario
- Para el Ingeniero de Software y Arquitecto Empresarial: La elección clara es Claude 4 (Opus/Sonnet). Su superioridad documentada en tareas de codificación complejas, integraciones con IDE y razonamiento agéntico proporciona un retorno de la inversión directo al acelerar el desarrollo y reducir los errores.
- Para el Científico de Datos, Analista Legal e Investigador Académico: La recomendación es Gemini 2.5 Pro. Su capacidad para ingerir y razonar sobre millones de tokens de texto, audio o vídeo es una capacidad revolucionaria para cualquiera que trabaje con conjuntos de datos masivos.
- Para la Startup, el Creador de Contenido y el Desarrollador Generalista: La principal recomendación es GPT-4o. Ofrece la mejor combinación de alto rendimiento, versatilidad en todas las modalidades y un precio inmejorable, lo que lo convierte en la base ideal para una amplia gama de aplicaciones sin arruinarse.
El análisis revela un panorama claro: la supremacía ha dado paso a la especialización. GPT-4o de OpenAI se ha establecido como la plataforma universal, ofreciendo un rendimiento de vanguardia a un coste que fomenta la adopción masiva. Gemini 2.5 Pro de Google es el campeón indiscutible del contexto, un motor analítico diseñado para devorar y sintetizar cantidades de datos sin precedentes. Y Claude 4 de Anthropic se ha labrado un nicho como el arquitecto de software de élite, donde la precisión y la seguridad en tareas de codificación complejas justifican su precio premium.
La tendencia empresarial emergente es la adopción de una estrategia multi-modelo. Las organizaciones más sofisticadas están orquestando flujos de trabajo en los que una tarea puede comenzar con Gemini para la ingesta de datos, pasar a Claude para la generación de código y utilizar GPT-4o para la interfaz de cara al usuario. Este enfoque de «lo mejor de cada casa» es el futuro de la construcción de aplicaciones de IA avanzadas, permitiendo a las empresas aprovechar la especialización de cada titán para lograr resultados que un solo modelo no podría alcanzar.
La verdadera frontera de la IA en 2025 no es solo construir modelos más potentes, sino aprender a orquestar inteligentemente estas herramientas especializadas y poderosas para resolver problemas que antes considerábamos irresolubles. La elección ya no es qué modelo usar, sino cómo usarlos todos.